

What is machine learning?

Machine learning (ML) is a form of artificial intelligence (AI) that enables software applications to predict outcomes more accurately without being explicitly programmed to do so. Machine learning algorithms use historical data as input to predict new output values.
Recommendation engines are a common use case for machine learning. Other popular applications include fraud detection, spam filtering, malware threat detection, business process automation (BPA), and predictive maintenance.
Why is machine learning important?

What are the different types of machine learning?
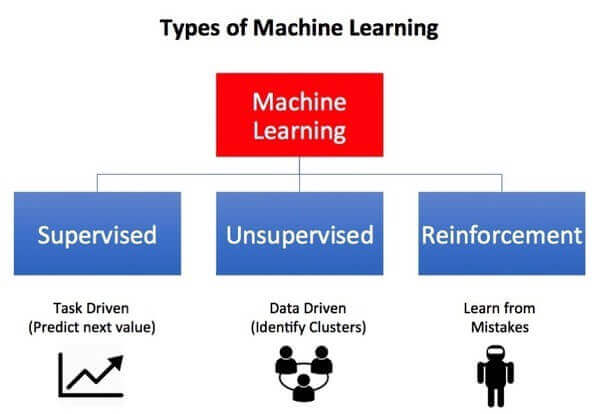
Supervised learning: In this kind of computer learning, data scientists supply algorithms with labelled training records and outline the variables they desire the algorithm to assess for correlations. Both the input and the output of the algorithm are specified.
Unsupervised learning: This type of machine getting to know involves algorithms that train on unlabeled data. The algorithm scans thru statistics sets searching for any meaningful connection. The data that algorithms educate on as well as the predictions or pointers they output are predetermined.
Semi-supervised learning: This approach to computing devices gaining knowledge of includes a combination of the two previous types. Data scientists may feed an algorithm typically labelled training data, however, the mannequin is free to discover the statistics on its own and develop its appreciation of the statistics set.
Reinforcement learning: Data scientists typically use reinforcement learning to instruct a computer to complete a multi-step system for which there are defined rules. Data scientists apply an algorithm to whole an assignment and supply it with tremendous or bad cues as it works out how to entire a task. But for the most part, the algorithm decides on its own what steps to take along the way.
Binary classification: Dividing data into two categories.
Multi-class classification: Choosing between more than two sorts of answers.
Regression modelling: Predicting non-stop values.
Ensembling: Combining the predictions of a couple of computing devices studying models to produce an accurate prediction.
Start Paraphrasing
How do unsupervised laptops gain knowledge of work?
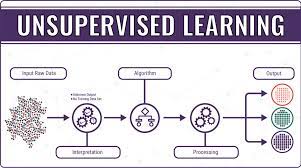
Clustering: Splitting the dataset into organizations based on similarity.
Anomaly detection: Identifying unusual information factors in facts set.
Association mining: Identifying units of gadgets in an information set that regularly take place together.
Dimensionality reduction: Reducing the range of variables in the facts set.
How does semi-supervised mastering work?
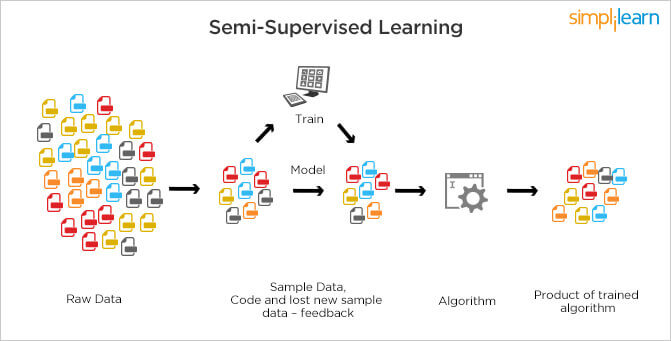
Machine translation: Teaching algorithms to translate language based on less than a full dictionary of words.
Fraud detection: Identifying instances of fraud when you only have a few advantageous examples.
Labelling data: Algorithms trained on small data units can research to apply information labels to larger units automatically.
How does reinforcement learning work?
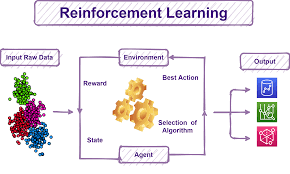
Robotics: Robots can study function tasks in the bodily world with the use of this technique.
Video gameplay: Reinforcement learning has been used to train bots to play several video games.
Resource management: Given finite assets and a described goal, reinforcement studying can help corporations graph out how to allocate resources.
Machine mastering is like statistics on steroids.
Who's the use desktop studying and what's it used for?
Today, computing device learning is used in a huge range of applications. Perhaps one of the most familiar examples of computer mastering in motion is the recommendation engine that powers Facebook’s information feed.
Facebook makes use of computer getting to know to customise how each member’s feed is delivered. If a member regularly stops to study a unique group’s posts, the recommendation engine will begin to show more of that group’s endeavour beforehand in the feed.
Behind the scenes, the engine is attempting to toughen recognized patterns in the member’s online behaviour Should the member alternate patterns and fail to study posts from that crew in the coming weeMachine-gainingks, the news feed will modify accordingly.
What are the advantages and hazards of machine learning?
Machine getting to know has considered use cases ranging from predicting customer behaviour to forming the operating gadget for self-driving cars.
When it comes to advantages, laptops getting to know can help organisations apprehend their clients at a deeper level. By accumulating patron information and correlating it with behaviours over time, computing device learning algorithms can study associations and asteamtteam teamwork product development and marketing initiatives to purchaser demand.
Some companies use laptop learning as an important driver in their commercial enterprise models. Uber, for example, makes use of algorithms to fit drivers with riders. Google makes use of desktop getting to know to surface the experience classified ads in searches.
But machine studying comes with disadvantages. First and foremost, it can be expensive. Machine getting-to-know tasks are normally pushed by way of statistics scientists, who command high salaries. These projects also require software infrastructure that can be expensive.
There is also the trouble of machine mastering bias. Algorithms trained on statistics sets that eliminate positive populations or comprise errors can lead to inaccurate fashions of the world that, at best, fail and, at worst, are discriminatory. When an organization bases core commercial enterprise tactics on biased models it can run into regulatory and reputational harm.
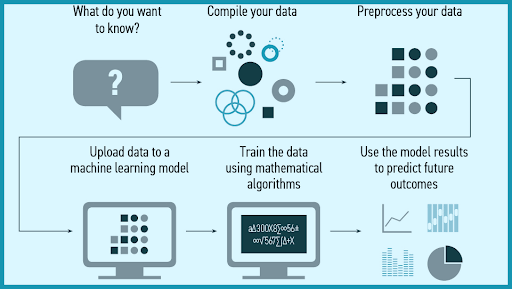
How to pick out the proper machine mastering model
The method of deciding on the right computer mastering model to remedy a problem can be time-consuming if now not approached strategically.
Step 1: Align the problem with doable statistics inputs that ought to be considered for the solution. This step requires assistance from information scientists and professionals who have a deep understanding of the problem.
Step 2: Collect data, format it and label the records if necessary. This step is commonly led by way of records scientists, with help from information wranglers.
Step 3: Chose which algorithm(s) to use and check to see how well they perform. This step is generally carried out by records scientists.
Step 4: Continue to fine-tune outputs until they reach a proper stage of accuracy. This step is typically carried out by records scientists with remarks from experts who have a deep understanding of the problem.
Importance of human interpretable machine learning
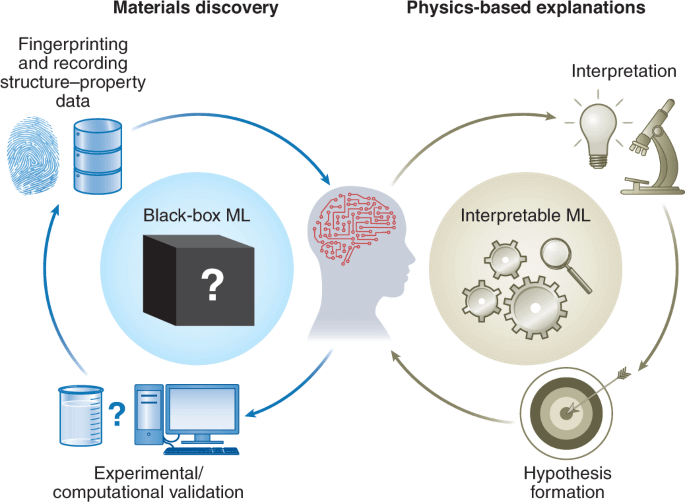
Explaining how a unique ML model works can be difficult when the mannequin is complex. There are some vertical industries where statistics scientists have to use easy laptop studying models due to the fact the business needs to explain how each choice was made. This is particularly true in industries with heavy compliance burdens such as banking and insurance.
Complex fashions can produce accurate predictions, but explaining individual he the output was decided can be difficult.
What Does the Future of Machine Learning
Machine Learning (ML) is so versatile and effective that it’s one of the most interesting applied sciences of our time. Amazon uses it, Netflix uses it, Facebook uses it, and the list goes on and on.
But, as with all different hyped technologies, there are a lot of misconceptions about computing devices gaining knowledge of too. In this article, we will discuss the future of computer studying and its value all through industries.
Machine learning works on the ideas of pc algorithms that study in a reflex manner thru trials and experiences. ML is a utility of Artificial Intelligence that lets in software purposes to assume outcomes with utmost precision. It makes a big difference in creating computer programs and tassistingcomputers to memorize besides human intercession. Machine-gaining knowledge forms an important role in the subject of corporations as it enables entrepreneurs to understand customers’ behaviour and enterprise functioning behaviour. Nowadays leading corporations like Google, Amazon, Facebook, Tesla, and many extra are correctly utilising these technologies, as a result, machine getting to know has come to be a core operational phase of functioning.








No Comments
Leave Comment